What is a rate limiter/ rate limiting?
Rate limiting can help in stopping unusual bot activities to certain extent. It also helps in reducing strain on web servers.
Bot attacks which can be stopped by rate limiting:
- Brute force attacks
- DoS and DDoS attacks
- Web Scraping
Rate limiting can be created using different algorithms, as a candidate you should ask interviewer about the kind of rate limiter you are trying to build.
Some questions that can be asked include:
- Rate limiter we are going to design is client-side rate limiter or server-side API rate limiter?
- What is the scale of the system? Is it being built for a large system or a small system?
- Rate limiter will be created inside application code or as a separate service?
- Environment in which we are creating it is distributed or not?
- Rate limit should accurately limit excess requests.
- Latency of rate limiter should be low, and it should work with less resources.
- Rate limiter should be able to handle exceptions, for example in case of throttling users should be informed.
- There should not be single point of failure in the system due to rate limiting going down.
Client Side Rate Limiting
Client Side rate limiting is usually not a reliable place to enforce rate limiting as it can be easily by passed by malicious users.
There is very less control over the client implementation this another reason for not having rate limiting at client side.
Server Side Rate Limiting
In server side rate limiting servers have limit on handling the user requests ensuring all the servers are used and no server is over burdened or unused. When user requests on one server exceeds the threshold value then request will be forwarded to the next server ensuring limiting the DDoS attacks.
Middleware Rate Limiting
Middleware rate limiter acts as an interface between client and server. This HTTP middleware allows restricting maximum number of allowed HTTP requests per second.
For example: API allows 2 requests per second, as soon as it will receive more than 2 requests it will throttle those requests and return 429.
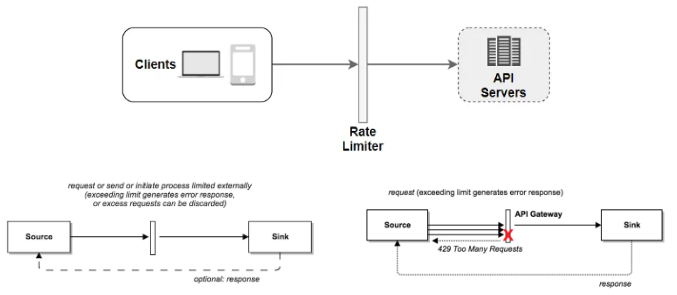
API Gateway is a component inside cloud microservices that enables rate limiting. It supports rate limiting, Authentication, whitelisting, SSL termination, etc.
Server side or Middleware which rate limiter to choose?
- If the programming language that company is working on currently is efficient enough to implement server side rate limiting then server side rate limiting can be used.
- If microservice you are working on is on cloud and already has a gateway then rate limiter can be added to the gateway.
Rate Limiting Algorithms
- Fixed Window
- Sliding Window Log
- Sliding Window Counter
- Token Bucket
- Leaking Bucket
Fixed Window Algorithm
- Timeline divided into fixed size windows and a counter is assigned to each window.
- As soon as a request is received counter is incremented by one.
- Once counter reaches the set threshold value, all the new requests are dropped and this happens until new time window starts.
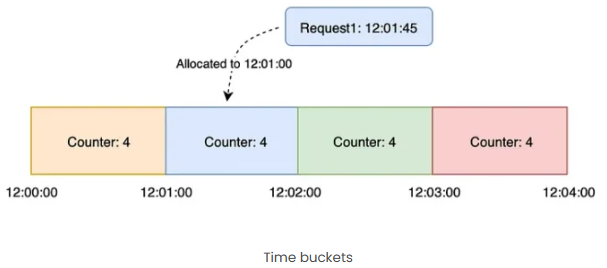
- Each window contains counter of 4
- When a request reached, request is allocated based on the FLOOR of timestamp.
- If request is received at 12:01:45 then it will be allocated to window of 12:01:00
- If counter is >0 then counter is decremented and process the request. Else, request is discarded.
Advantages of Fixed Window Algorithm
- Easy to understand
- Memory Efficient
- Low latency
Disadvantages of Fixed Window Algorithm
- Load of sudden burst of traffic near boundary of the window.
- If counter runs out at the start of the window, clients will need to wait for long reset window.
Sliding Window Log Algorithm
- Log is used to store processed requests along with their timestamps. Timestamp and similar data is usually stored in a cache example: Redis cache.
- If the log size is lower than the max allowed count , we accept the request and add it to the log otherwise we reject it.
- When a new request is received all the outdated timestamps are removed. Outdated timestamps are the one those are older than the start of current time window.
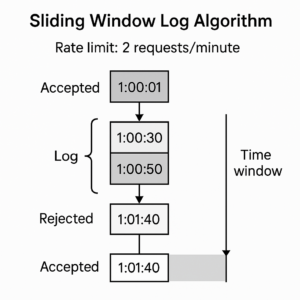
In the below example, rate limiter will allow only 2 requests/minute.
- Log is empty when a new request is received at 1:00:01. Therefore, this request is accepted.
- After sometime a new request is received at 1:00:30 this is also accepted and inserted into the window. Now log size is equal to max size allowed i.e. 2.
- Now a new request is received at 1:00:50, the timestamp inserted into the log. After insertion the size becomes greater than 2 thus, this request is rejected but timestamp remains in the log.
- New request arrives at 1:01:40. Requests in the range [1:00:40-1:01:40] belong to the same group with in latest time frame. But request before 1:00:40 are outdated and thus, outdated timestamps 1:00:01 and 1:00:30 are removed from the log. After remove operation size again becomes 2 and thus, request is accepted.
Advantages
Ensures rate limit is strictly adhered to any given point in time.
Disadvantages
More memory is required as event the rejected request is stored in the memory.
Sliding Window Counter Algorithm
Sliding window counter algorithm is a combination of fixed window counter and sliding window log algorithms.
- The entire window time is broken down into smaller buckets. The size of each bucket depends upon how much elasticity is allowed for the rate limiter.
- Each bucket stores the request corresponding to the bucket range.
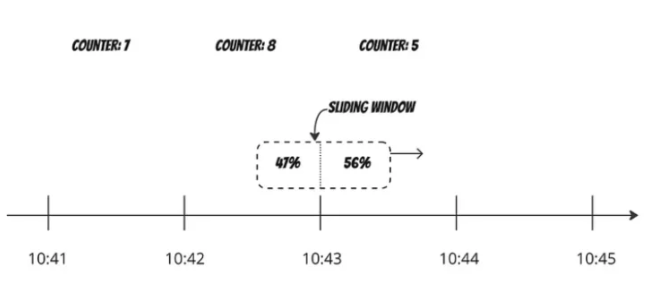
Let’s calculate the weighted counter for the previous fixed time window. Then, we can estimate how many requests are in the current sliding window.
The formula to calculate number of requests in a rolling window is :
Requests in current window + request in previous window * overlap percentage of rolling window and previous window
For the above example:
previous window request count = 8
current request window count = 5
previous window count weight = 0.47
Number of requests in current sliding window: 5 + 8 * 0.47 = 8.76 -> ~9
So if the rate limiter allows maximum of 10 requests in a minute, the current request can go however limit will be reached after receiving one more request.
Advantages
- Works well in most of the scenarios and smooths out spikes in traffic since rate is based on the average rate of the previous window.
- Memory efficient as only counts are stored.
Disadvantages
- Works only for not-so-strict look back window times, especially for smaller unit times. It is an approximation of actual rate because it assumes the requests in previous window are evenly distributed.
Token Bucket Algorithm
So how does Token Bucket algorithm work?
- The token bucket algorithm is based on an analogy of a fixed capacity bucket into which tokens are added at a fixed rate.
- Before allowing an API to proceed, the bucket is inspected to see if it contains at least 1 token at a time.
- If so, one token is removed from the bucket, the API is allowed to proceed. In case there are no tokens available, the API is returned saying that the quota has exceeded that window.
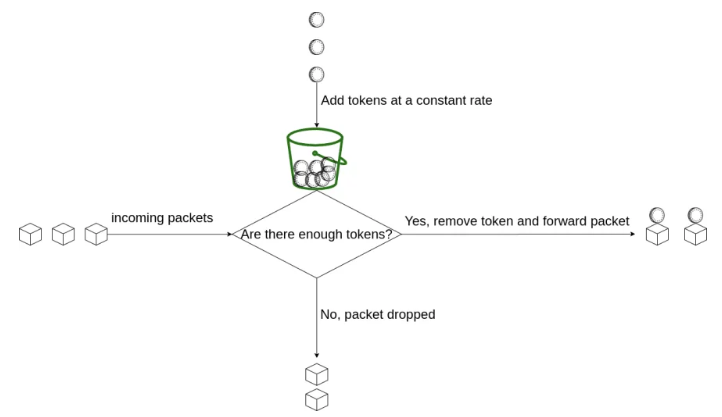
Token bucket algorithm works on two parameters:
- Bucket Size : Maximum number of token allowed inside the bucket
- Refill Rate : Number of token inserted back to the bucket every second.
- If throttling requests on the basis of IP addresses is required then each IP address requires a bucket.
Advantages
- Easy to understand and implement
- Memory efficient
- Allows burst of traffic for short period
Disadvantages
- Bucket size and refill rate require proper tuning otherwise rate limiting will not work as expected.
Leaking Bucket Algorithm
Leaky bucket algorithm is similar to token bucket except the fact requests are processed at a fixed rate in it. The idea behind the algorithm is simple, imagine that there is a bucket of tasks that’s being filled with incoming tasks. The bucket also has holes at the bottom that tasks can drip down the task processor.
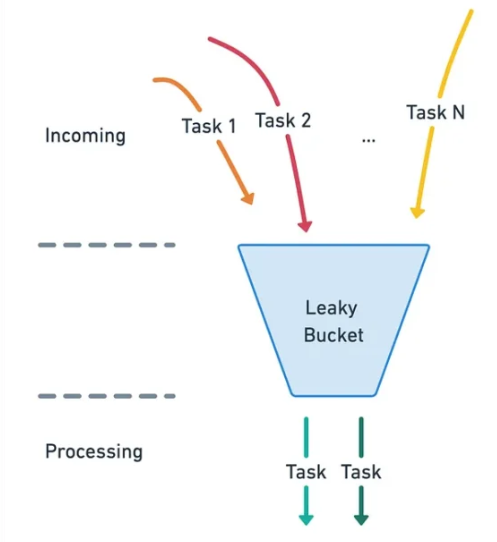
There are a few states the bucket may be in:
- empty
- full
- has some tasks being processed but neither empty nor full.
As long as the bucket is not full, it’ll keep handing over tasks to the processor at a constant rate. When it’s full, it should “overflow” and no incoming tasks are allowed in until some tasks are done. It is usually implemented with a first-in-first-out (FIFO) queue.
Algorithm
- The system checks if bucket/queue is full. If queue is not full then request is added to the queue. Else, request is dropped/discarded.
- Requests are pulled from the bucket/queue at regular intervals.
Advantages
- Memory efficient
- Requests are processed at fixed rate
Disadvantages
- If old requests are not processed in time then new requests will be rate limited.
- Fine tuning of 2 parameters is required.
High Level Design
Usually such counter are stored in in-memory cache as it is fast and supports expiration based on time. There are generally two commands that offered by Cache such as Redis:
- INCR : Increase the counter by 1
- EXPIRE : Every counter has a timeout limit that is set, if the timeout reaches/expires then counter is automatically deleted.
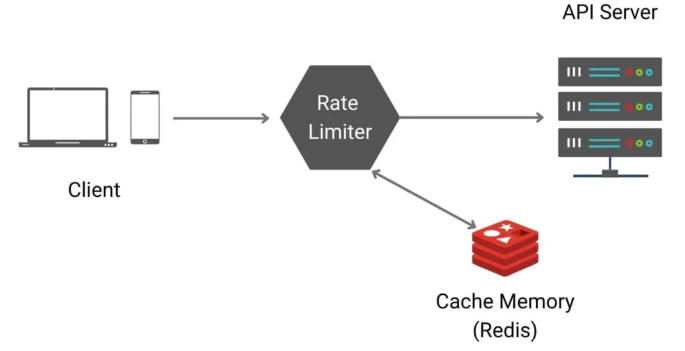
- Client/User sends a request to rate limiter.
- Rate limiter checks the counter inside cache memory if the limit has reached or not.
- If limit is reached, reject the request. Else accept the request and system will increment the counter.
Design In Depth
- How are rate limiting rules created? Where will these rules be stored?
- How rate limited requests will be handled? What are various strategies to handle it?
- How rate limiting works in a distributed environment?
- How rate limiter can be optimized?
In this section we will answer all the above questions one by one.
Rate Limiting Rules:
This is what a rate limiting rule commonly looks like:
Example1:
domain: messaging
descriptors:
- key: message_type
value: sales
rate_limit:
unit: week
requests_per_unit: 5
As per the above rule rate limiter is configured to allow maximum 3 sales messages in a week
Example2:
domain: auth
descriptors:
- key: auth_type
value: login
rate_limit:
unit: minute
requests_per_unit: 3
As per the above rules rate limiter is configured to allow maximum 3 user login in a minute.
Handling Rate Limited Requests
How does a client know the number of requests left before being throttled?
X-Ratelimit-Remaining: The number of requests left within the window which will be allowed.
X-Ratelimit-Limit: number of calls the client can make per time window.
X-Ratelimit-Retry-After: The number of seconds client has to wait to make a request again without being throttled.
Now if a user sends too many requests and API returns 429 response then rate limiter will return X-Ratelimit-Retry-After header to the user.
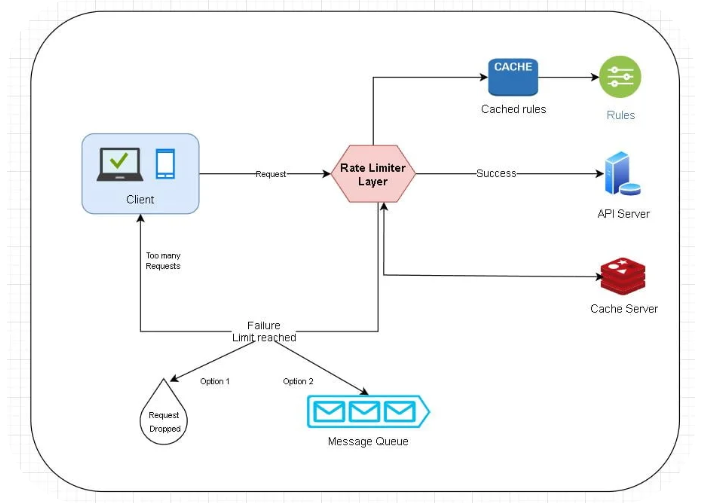
- Workers pull rules from the disk on regular intervals and store it to the cache.
- Client send a request to rate limiter.
- Rate limiter checks the rules from the cache.
- If request meets the rules and is not rate limited then it accepts the request and forward it to the server and counter increases in cache.
- If the request is rate limited then rate limiter will return 429 status code and now request can either be dropped or be added to the queue for later processing.
Rate Limiter in a Distributed Environment
- Race Condition: Rate limiter on getting a request checks performs a read on Cache, it checks if counter has reached threshold or not, incase not it will increase the counter value by 1 and update the cache counter. Now assuming value of counter in cache is 2 and two requests concurrently read this value and update the counter value by one and write it back without checking it. Now both requests will assume they have correct value 3 whereas correct counter value should be 4. Now to avoid race condition one of the ways would be to introduce locks but locks will significantly slow down the system. Sorted set data structure in Redis and Lua Scripts are commonly used to solve this problem
- Synchronization Issue: While working in distributed environment it is important to consider synchronization issue. With increase in the number of users a single rate limiter server will not be enough. Thus, multiple rate limiter servers will be required and synchronization between then is important. As it is important to keep a track of requests belonging to user in rate limiter, if from the same user one request goes to one rate limiter server and second goes to another then rate limiter will not solve the purpose as this is a synchronization issue. One of the ways to solve synchronization issue is to use sticky session that will allow client traffic to send request to the same rate limiter. But this is not a recommended approach as it is not scalable and flexible. A better solution would be to use centralized data stores like redis.
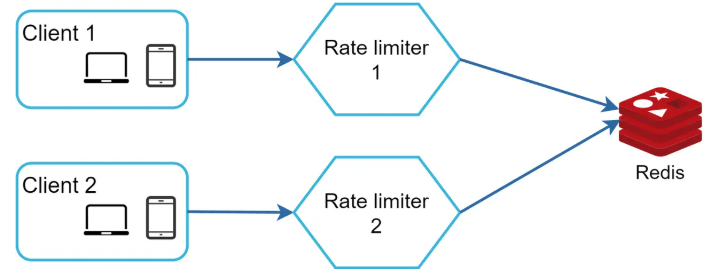
Rate Limiter Performance Optimization
- Multi Data Center setup as this will reduce latency for users spread at various locations. Traffic will be routed to the closest server to reduce latency.
- Synchronize data with eventual consistency
- Rate limiting algorithm is effective
- Rate limiting rules are effective