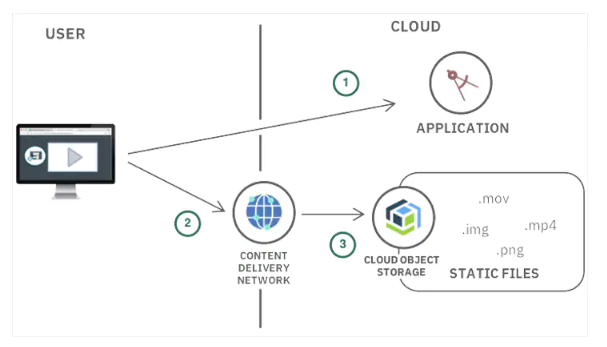
If you’re planning to build a complex network you need to first start small one step at a time. To start small something simple we will talk about single server setup in this post.
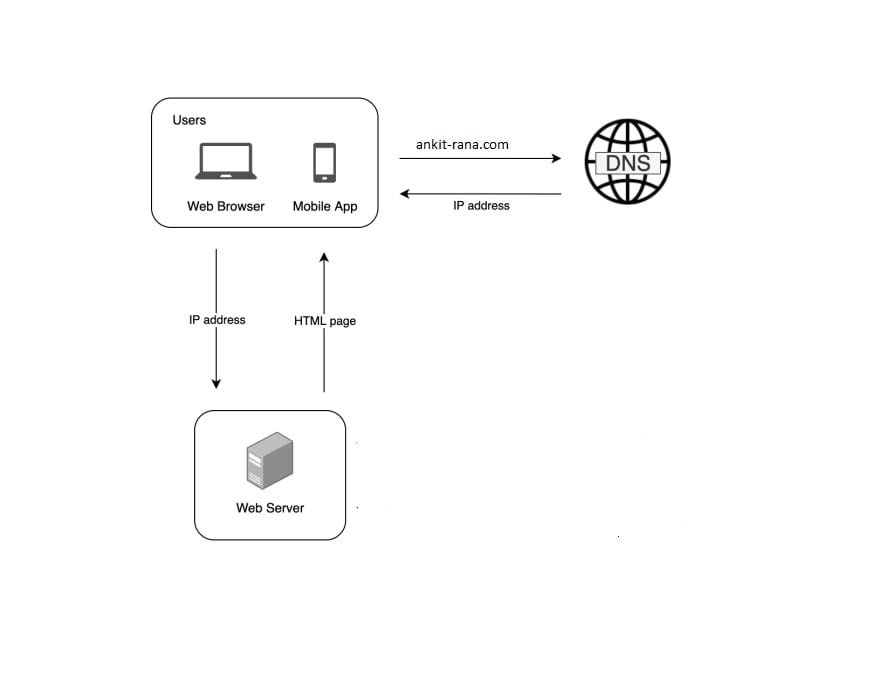
Request flow from User to the web server:
-
- User is going to access website through domain name such as ankit-rana.com.
-
- Internet Protocol (IP) is returned to the web browser or app via DNS (Domain Name System) Look-up for example: 12.123.23.200
-
- Once IP is obtained, web server receives HTTP (Hyper Text Transfer Protocol) request directly.
-
- Usually web-server returns HTML pages or JSON as response.
As the scale of your service or application increases i.e. more and more new users onboard one server will no longer be enough and there will be a requirement for multiple servers. Also, to save the information of your users you need to a database. Database will act as your persistent storage.
With increase in number of requests its important to scale your server and separating web tier and data tier is an important step to scale the servers and databases independently.
Which database to choose?
| Relational Database | Non-Relational Database | |
| 1 | Relational databases represent and store data in tables and rows. You can perform join operations using SQL across different database tables. | Non-Relational Databases are grouped into four categories: key-value stores, graph stores, column stores, and document stores. Join operations are generally not supported in non-relational databases. |
| 2 | Relational databases are also called a relational database management system (RDBMS) or SQL database. | Non-Relational databases are also called NoSQL databases. |
| 3 | Example: MySQL, Oracle database, PostgreSQL, etc. | Example: CosmosDB, Cassandra, HBase, Amazon DynamoDB, etc. |
When to use Non-Relational databases?
-
- Application requires super-low latency.
-
- Data is unstructured, or there isn’t any relational data.
-
- There’s only need to serialize and deserialize data (JSON, XML, YAML, etc.).
-
- There’s massive amount of data to store.
You can scale your applications in two ways:
- Vertical Scaling
- Horizontal Scaling
| Vertical Scaling | Horizontal Scaling | |
| 1. | Vertical scaling is referred as “scale up”, which means the process of adding more resources (CPU/Memory) to your servers. | Horizontal scaling is referred as “scale-out”, which means it allows you to scale by adding more servers into your pool of resources. |
| 2. | Only suitable for applications with low traffic and is simpler. | It is more desirable for large scale applications. |
| 3. | Hard limitation on the number of resources that can be configured to a single server. | No limitation on resources as multiple servers can be added. |
| 4. | No failover and redundancy, application will go down incase server goes down. | Multiple instance of the same application is running at a time so incase on of the instance goes down other one will take its place and distribute the load. |
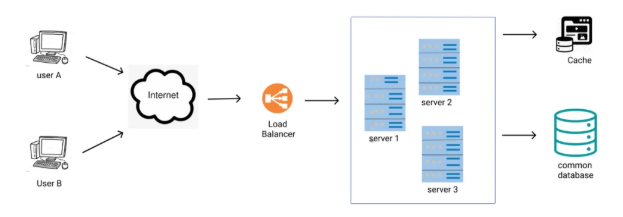
Load Balancer
Load balancer is used to distribute incoming traffic among web servers, that are defined in a load-balanced set.
Your service can run in multiple regions, example South Central US, East US, etc. Each instance running in these regions/clusters will will have a unique cname and you directly interact with that instance using this cname. But your client user can’t manage all these cnames to interact with your service. Load-Balancer will manage the traffic to all these cnames internally depending upon the configuration set at GSLB (Global Server Load Balancer) .
The service will have an ingressHost i.e. GSLB endpoint which user/client will interact and internally from this ingressHost cnames will get the request from load balancer.
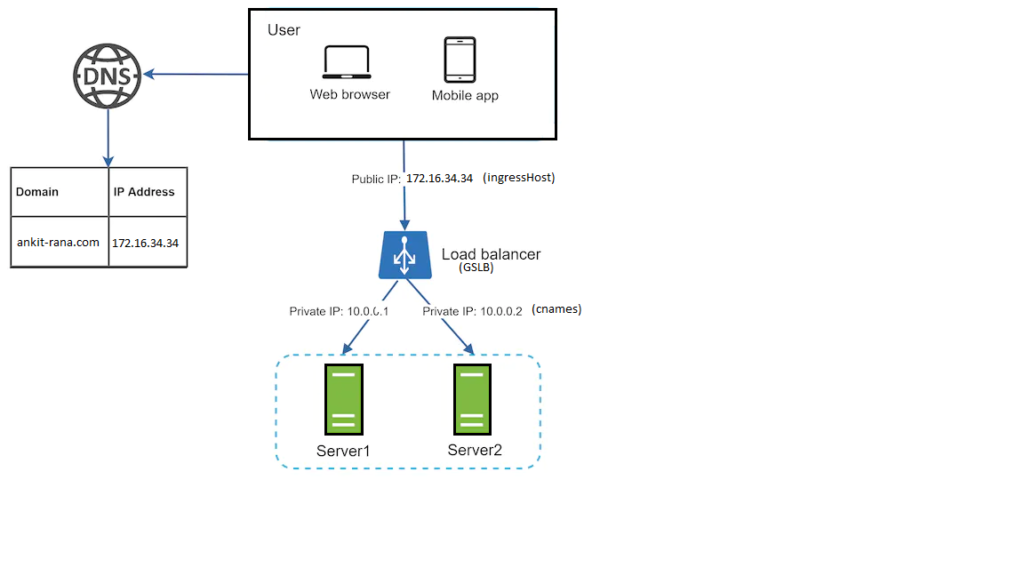
User connect to the public IP (ingressHost) of the load balancer. Due to load balancer in place, clients can’t reach web servers directly. To enhance the security, private IPs (cnames) are used for communication between servers. Private IP is an IP address that is reachable only between servers with in the same network (intranet). It is unreachable over the internet. The load balancer acts as an intermediate layer that communicates with web servers through private IPs.
Load balancer will take care of failover issues and will be redirecting traffic to the healthy instances of the service. Thus, it has helped in improving the availability of web tier.
How does load balancer act in failover situations?
- If server 1 goes down, all the traffic will be routed to server 2. This prevents the website from going offline. We will also add a new healthy web server to the server pool to balance the load, once the new server is up load will be distributed again by load balancer.
- Incase resources are less to handle the traffic load of the website, the load balancer will again come into the picture to scale the infra. All that is needs is to add more servers to the web server pool, and then once the set threshold for resources is met load balancer automatically increase the server and starts to send requests to them.
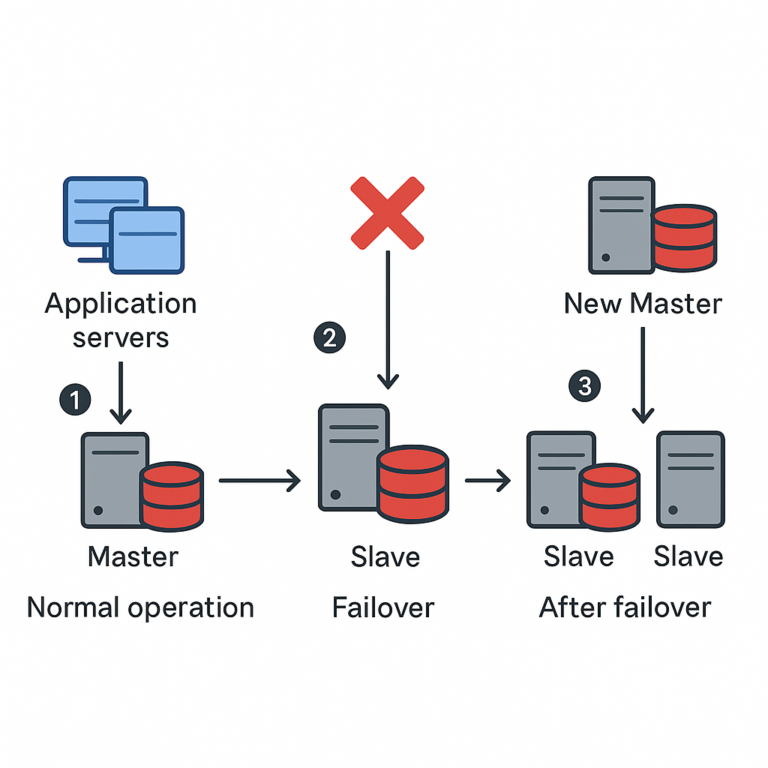
In order to handle server failover, we learnt about Load Balancer and how shifts traffic from one server to another. The same situation can happen for database also what if your database goes down? How are you going to handle this situation?
Similar to multiple servers inside Database also we have multiple instances or database replicas. Each of these replicas are kept in sync by the process of Database Replication. “Database Replication process can be used in many Database Management Systems, usually it is with a master/slave relationship between the original (master) and the copies (slaves)”.
Usually all the write operations are supported only by master database and slave database serves read operations. Slave database gets the copies of data from master database by database replication. Write operations include the commands which modify the data example: insert, delete, update, etc. The number of read operations that happens inside a database is usually greater than the write operations thus number of slave databases in a system is larger than number of master databases.
What are benefits of database replication?
Master-Slave architecture increases the overall performance of the database as write operations happen only at master database and reads happen at slave databases. This separation of roles improves the performance by increasing parallelism.
Incase of DR / disaster is one of the database server goes down then still data will be saved/preserved as it is present at multiple locations. Database replication will ensure no data is lost from any database server.
High availability of your website is ensured by database replication as even if one of the database server goes down still other database servers will serve the requests.
What if the master database goes down?
If master database goes down/offline then a slave database will become master database, all the write operations will be executed temporarily on the newly created master database. Along with it a new slave database will be created which will replace the previous one for data replication. In real world scenarios promoting a slave database to master database is a complex process as slave database may or may not be upto date or sync with master database. The data which is missing or absent needs to be recovered manually via some scripts. Other ways to solve this problem would be to have multi-master database model or better data replication process such as circular replication, not to mention these methods will increase the complexity of your setup.
What if slave database goes down?
If there’s only one slave database and that goes down then master database will serve both read and write traffic. Also, another slave database will be created after finding the issue and traffic will again be re-routed to slave database. Incase there are multiple slave databases then read-operations will be routed to another slave database which is still healthy and here also, another slave database will be created after finding out the issue.
Multi-Master Database Setup
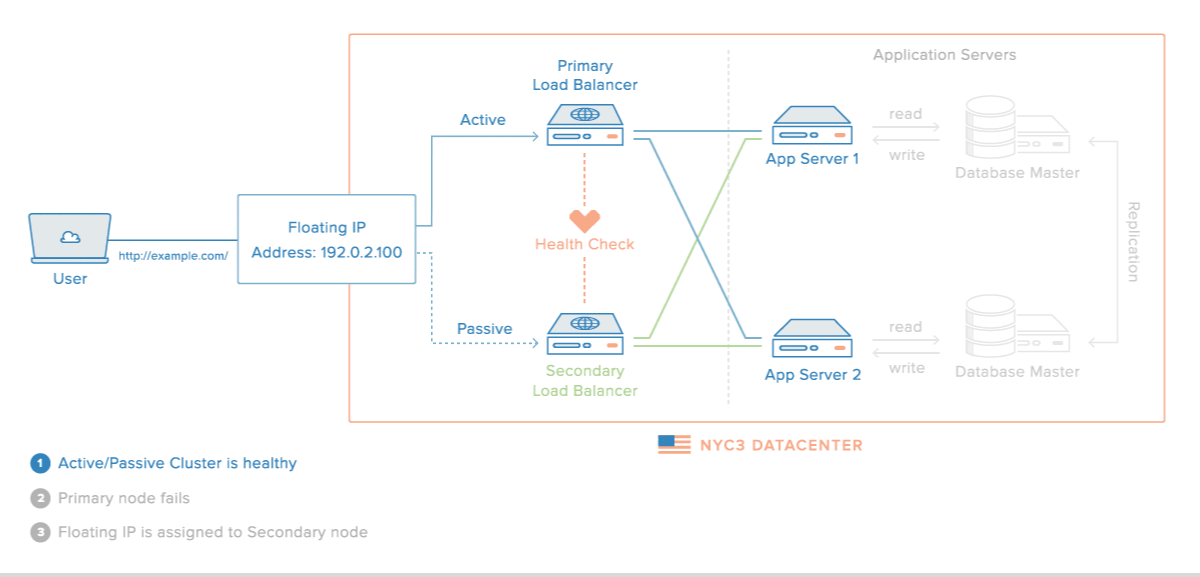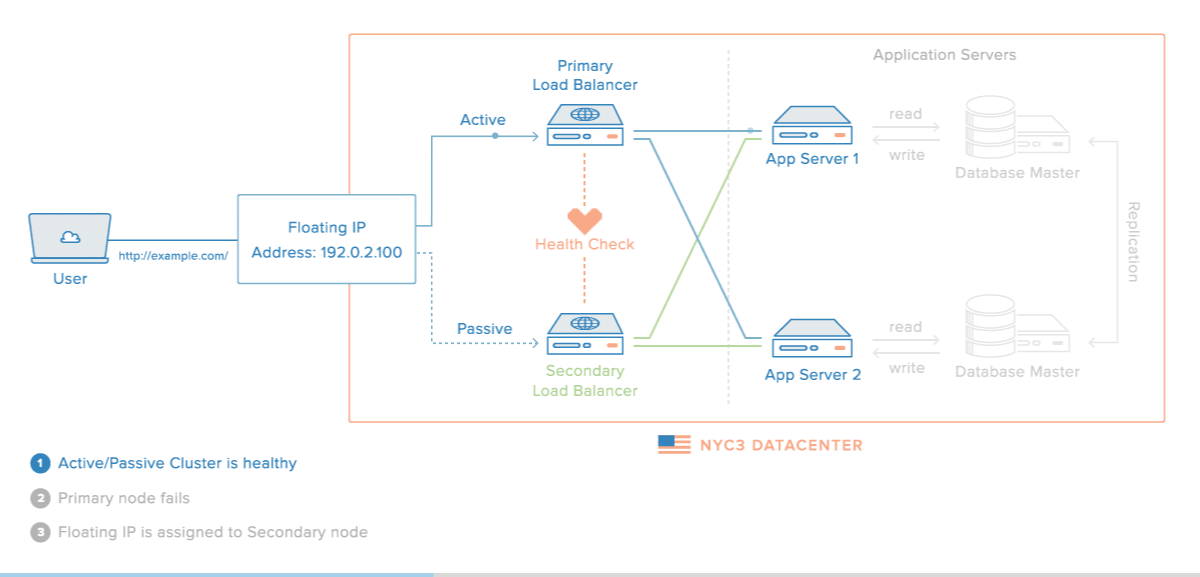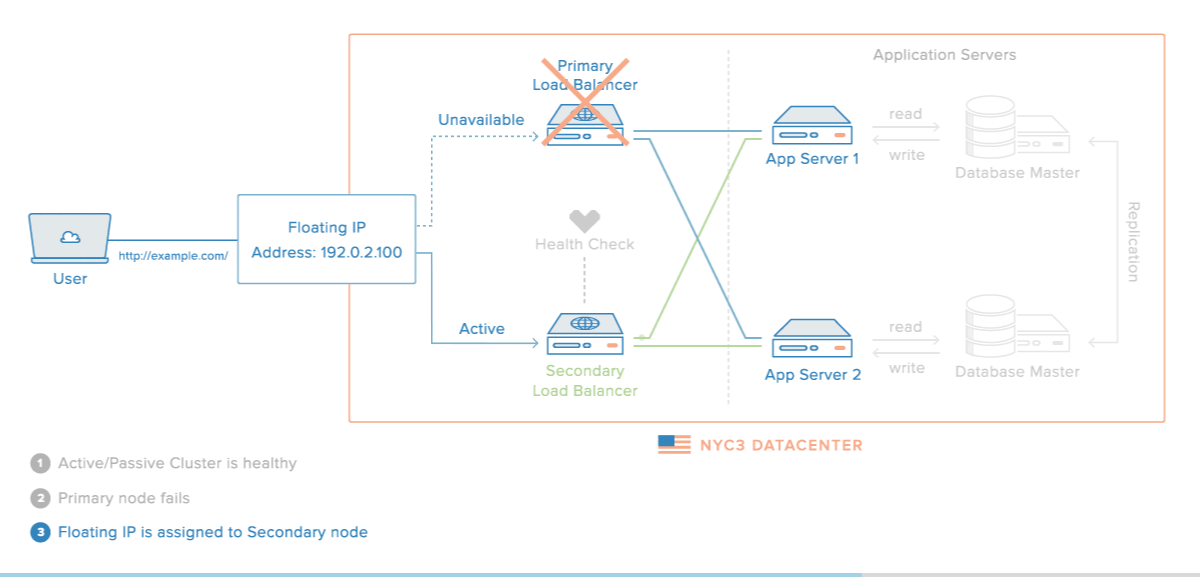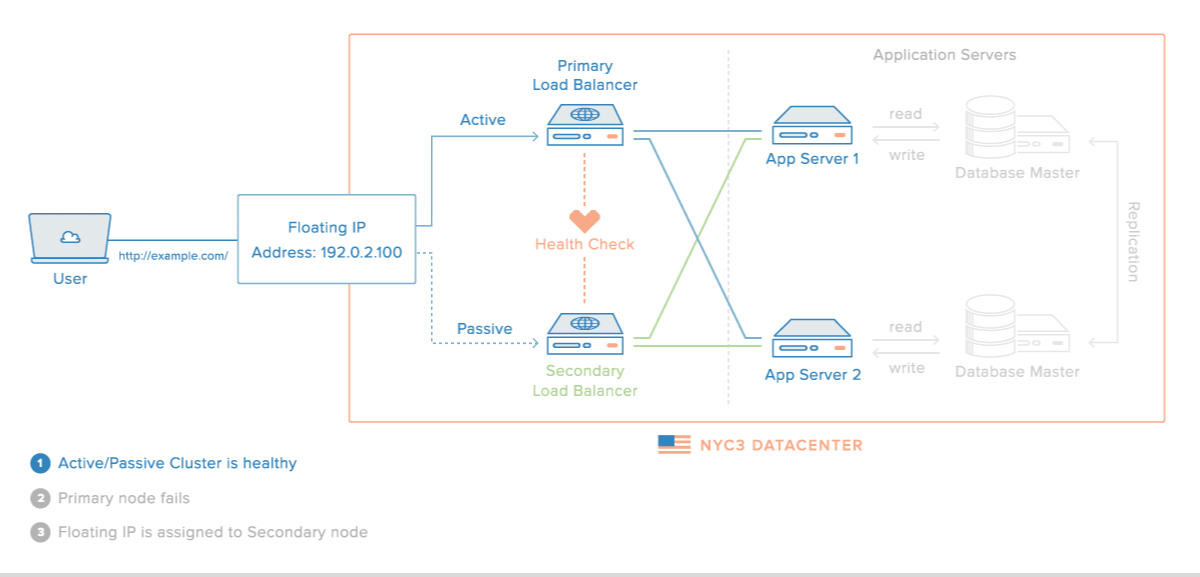
Master Slave Database Setup
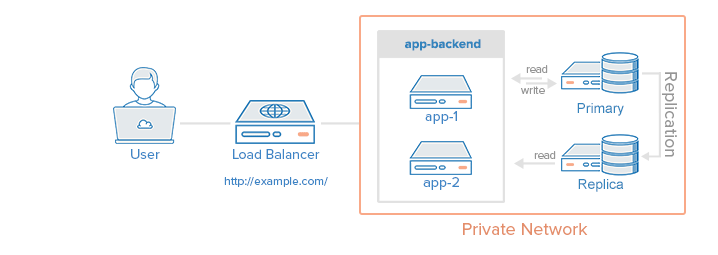
Loading data from the database every time user makes a similar request can increase the API response time. In such cases Cache can be used.
What is a Cache?
Cache is a temporary data storage layer which is much faster than database. Cache works like map, which has a key and value every time you enquire for that key it’s corresponding value is returned. The benefits of having separate Cache will create better performance and would also reduce the DB hits or Database calls.
User makes a request to the application, now application is going to check for the given request/key data is present inside Cache or not, if Cache contains the data then read from the Cache. If Cache doesn’t contain data then read from Database and save this data into the Cache. This process is called read-through cache.
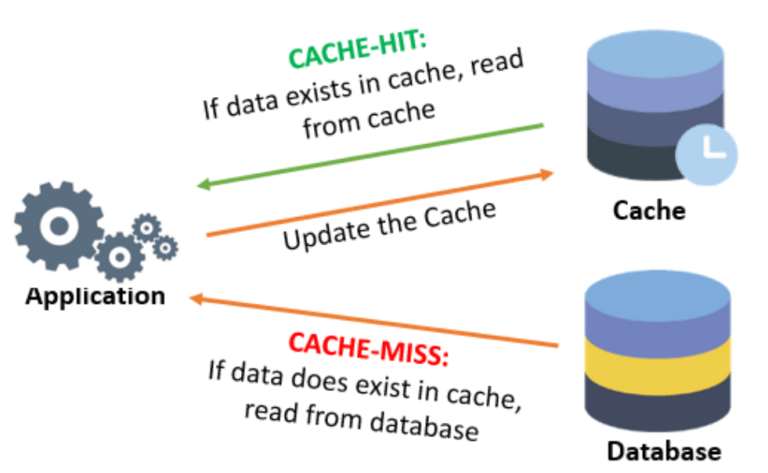
When to use a Cache?
Cache should be used when the data is read frequently but modified infrequently. Data inside Cache is stored inside volatile memory and thus it is not created for persisting data. If Cache server restarts then the data present inside memory will be lost. Therefore, you can not just rely on Cache for storing all your data and you should always store data inside persistent data stores.
Every cache that you configure should have an expiration policy. Once cached data expires it will be removed from the cache. If expiration policy is not in place then data inside Cache will be stored permanently unless Cache memory becomes full. Your expiration date should should not be too short as this will cause Cache misses and database calls will increase significantly. At the same time it should not be too long as the cached data can become stale.
It is important to keep your database and cache in sync. Inconsistency can happen because of database being modified and not updating cache in the same transaction.
You should have cache servers across different data centers as if a single cache server exists then there can be “A Single Point of Failure” (SPOF) and it will stop entire system from working. One more thing that can be done to present failure would be to configure memory more than that is required.
What will happen if the Cache memory becomes full?
Once Cache memory is full, any new items which are added to it will cause removal of existing items. This process is known as Cache Eviction. Least-recently-used (LRU) is one of the most popular Cache eviction policy.