In the realm of distributed databases, where replication is a necessity for high availability and low latency, there exist certain tradeoffs that must be considered. These tradeoffs revolve around factors such as read consistency, availability, latency, and throughput. The PACELC theorem succinctly encapsulates these tradeoffs – in the event of a partition (P), a choice must be made between availability and consistency (AC), and in normal operation (E), a tradeoff between latency and consistency (LC) must be made.
The strong consistency model, which ensures the most recent data is read, is often seen as the ideal in data programmability. However, it comes with a cost – higher write latencies due to data needing to be replicated and committed across vast distances. Additionally, it risks reduced availability during failures because data replication and commitment can’t always be achieved in every region. On the other hand, eventual consistency offers higher availability and better performance, but it can make application programming more challenging due to potential inconsistencies across different regions.

Consistency Levels in Azure Cosmos DB
Azure Cosmos DB, a distributed NoSQL database service by Microsoft, offers a distinct advantage over most commercially available distributed databases in the market. While others offer only strong and eventual consistency options, Azure Cosmos DB provides five well-defined consistency levels. These levels, in descending order of strength, are: Strong, Bounded staleness, Session, Consistent prefix, and Eventual.
- Strong: With the strong consistency model, linearizability is guaranteed. This means that requests are served concurrently, and the reads are always the most recent committed version of an item. Clients will never encounter an uncommitted or partial write, ensuring the latest committed write is always read.
- Bounded Staleness: This model ensures that the lag in data between any two regions is always less than a specified limit. The “staleness” can be configured based on the number of versions (K) of an item or a time interval (T). This model works best for globally distributed applications using single-region write accounts with two or more regions, where near strong consistency across regions is desired.
- Session: In the session consistency model, within a single client session, reads honor the read-your-writes, and write-follows-reads guarantees. The model assumes a single “writer” session or multiple writers sharing the session token. This model is the most widely used consistency level for both single region and globally distributed applications.
- Consistent Prefix: Under this model, updates made as single document writes experience eventual consistency. However, updates made as a batch within a transaction are returned consistent to the transaction in which they were committed.
- Eventual: The eventual consistency model is the weakest form of consistency where a client may read values that are older than the ones it read in the past. This model is ideal for applications where ordering guarantees are not required.
Strong Consistency
Understanding the concept of strong consistency is crucial when dealing with distributed databases. This model is the cornerstone of data programmability and plays a significant role in maintaining the integrity and reliability of the information across different regions. Strong consistency, as the name suggests, is the most stringent level of consistency. It provides a linearizability guarantee, which means that every read operation receives the most recent write operation or an error. In simpler terms, strong consistency ensures that your data is always up-to-date across all regions at any given moment. This level of consistency is like a symphony, harmonizing reads and writes across all regions, ensuring that each note or operation hits the right chord. For instance, if data is written to a region, say “West US 2”, strong consistency ensures that when you read this data from any other region, you get the most recent value. This harmony is achieved through the process of data replication and commitment across all regions. But, this symphony comes at a cost. Replicating and committing data across regions takes time, leading to higher write latencies. This is like waiting for the echo of your note to reach the farthest corner of a concert hall. The time taken for the note (data in our case) to reach that corner is the write latency. Furthermore, strong consistency might experience a dip in its performance during failures. This is because it’s not always possible for the data to replicate and commit in every region during such instances. Therefore, although strong consistency guarantees the latest read, it may come with its own challenges in terms of performance and availability. Despite these trade-offs, strong consistency is crucial in scenarios where reading the most recent data is of utmost importance. It ensures that all copies of the data are the same across all regions at any given time, thereby upholding the integrity of the data.
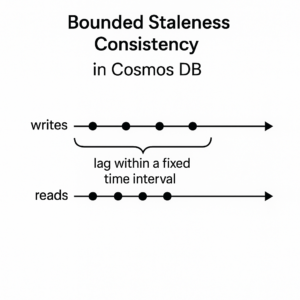
Bounded Staleness Consistency
Bounded staleness consistency is a model that tries to strike this balance by allowing a specific lag or ‘staleness’ between data in different regions. It is best suited for applications that require near strong consistency across regions but can tolerate slight delays in data propagation.
Now, let’s delve deeper into the concept of bounded staleness consistency and how it operates in both single-region write accounts and multi-region write accounts.
Bounded Staleness in Single-Region Write Accounts
For single-region write accounts with two or more regions, data replication happens from the primary region to all secondary, read-only regions. Occasionally, there could be a replication lag from the primary region to the secondary regions. This is where bounded staleness comes into play.
In the bounded staleness consistency model, the lag between any two regions is always less than a specified amount. This amount can be defined in two ways: by the number of versions (K) of an item or by the time interval (T) by which reads might lag behind the writes.
This means, when you choose bounded staleness, you can define the maximum staleness of the data in any region. If the data lag in a region exceeds the configured staleness value, writes for that partition are slowed down until staleness is back within the defined limit.
Bounded Staleness in Multi-Region Write Accounts
In multi-region write accounts, data is replicated from the region it was originally written in to all other writable regions. Like in single-region write accounts, there may be a replication lag from one region to another.
The concept of bounded staleness applies here as well. However, its implementation in multi-region write accounts can be tricky. It’s important to note that in a multi-write account, relying on bounded staleness consistency could be counterproductive as it introduces a dependency on replication lag between regions. This should ideally be avoided as data should be read from the same region it was written to.
Maximizing Data Freshness with Bounded Staleness
The main advantage of bounded staleness consistency is that it allows you to control the freshness of data across different regions. By setting the maximum number of versions or the time interval, you can ensure that the data read by your application is as fresh as possible, without sacrificing availability or performance.
This makes bounded staleness consistency an excellent choice for globally distributed applications using single-region write accounts with two or more regions. The ability to configure the maximum staleness of data makes it easier to meet the specific needs of your application and provide a consistent user experience, irrespective of where your users are located.
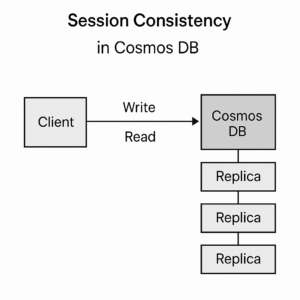
Session Consistency
Session consistency is an intermediate consistency level that ensures a balance between strong consistency and the performance benefits of eventual consistency. It is predominantly used in both single-region and globally-distributed applications.
At its core, session consistency ensures that within a particular client session, the system guarantees read-your-writes and write-follows-reads. In simpler terms, if a client writes some data, it can immediately read that data back. Similarly, if a client reads some data and then writes based on that read, the system ensures that the write operation follows the read.
The fascinating aspect of session consistency is that it provides these guarantees while maintaining high availability and low latency, similar to eventual consistency. However, these guarantees are applicable only within a single client session. This means that for other sessions or clients, the data might not be immediately available or consistent.
This consistency level is ideal for scenarios where an application is designed to operate in the context of a user session. For instance, in a shopping cart scenario, when a user adds an item to their cart, they expect to see that item in the cart immediately. Session consistency ensures this behavior, making it a popular choice among developers.
Role of Session Tokens in Session Consistency
Session tokens play a vital role in maintaining session consistency. They act as a “stamp” of the latest data read or written by a client in a specific session. After every write operation, the server sends an updated session token to the client. The client, in turn, caches these tokens and uses them for subsequent read operations.
By sending the session token with each read request, the client informs the server of the last known state. The server ensures that the client receives data that is at least as fresh as the data associated with the token. If the requested data is not available with the replica the read operation is issued against, the client retries the operation against another replica. This process continues until the server fetches the data corresponding to the session token.
However, it is essential to note that session tokens are tied to individual partitions. This means a token generated for a particular partition cannot be used to ensure read-your-writes for a different partition. Also, if a client is recreated, its cache of session tokens is also re-created. Until subsequent write operations occur to rebuild the client’s cache of session tokens, read operations behave as reads with Eventual Consistency.
Consistent Prefix Consistency
Consistent Prefix Consistency fundamentally pertains to the synchronization of data updates across multiple regions and nodes. While it is less stringent than Strong Consistency, it offers a balance between performance and consistency that can be highly beneficial for certain applications.
Imagine you’re playing a game of telephone, where a message is passed from one person to the next in a line. In the context of Consistent Prefix Consistency, the rule would be this: The message you hear can be an older version but it must always be in the same order as spoken.
Translating this to database operations, Consistent Prefix Consistency ensures that replicas of the data never see out-of-order write operations. This simply means, if we have multiple data updates or ‘writes’, they will be seen in the order they were committed, even if some lag behind others in terms of when they are seen.
Guarantees of Consistent Prefix Consistency
In the world of Consistent Prefix Consistency, the guarantees differ between single document writes and batch writes within a transaction. Let’s delve into each of these scenarios:
- Single Document Writes: For operations that involve writing to a single document, Consistent Prefix Consistency provides eventual consistency. This means that while the updates may not be instantly seen across all replicas, they will eventually be consistent. The order of these updates is preserved, ensuring that no replica sees the updates in a different order.
- Batch Writes within a Transaction: Whereas, for batch writes within a transaction, Consistent Prefix Consistency ensures that all updates made within the transaction are seen together. Let’s take an example where two updates are committed within a transaction, first to Document1 and then to Document2. Under Consistent Prefix Consistency, a read operation will either see both updates, or neither, but never one without the other. This ensures that the state of the database remains consistent throughout the transaction.
It is also important to note that like all consistency levels weaker than Strong, writes in Consistent Prefix Consistency are replicated to a minimum of three replicas in the local region, with asynchronous replication to all other regions.

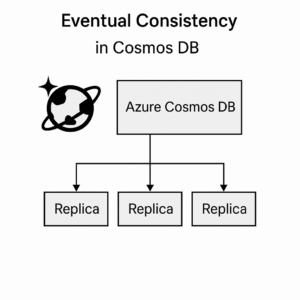
Eventual Consistency
Eventual consistency is a model that ensures that if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. In simpler terms, if you stop writing data, eventually all the read requests will yield the same output.
Eventual consistency is considered the weakest form of consistency due to its latency in reflecting the updated data across all nodes. It doesn’t guarantee immediate consistency across all nodes in a database; instead, it assures that all nodes will eventually be consistent.
An important thing to remember about eventual consistency is that it’s possible for a client to read older values, meaning that a client may read values that are less recent than ones it read in the past. This may seem like a limitation, but it’s a trade-off for other benefits such as high availability and low latency.
The Mechanics of Eventual Consistency
In a database leveraging the eventual consistency model, like Azure Cosmos DB, data is written to a minimum of three replicas (in a four replica set) in the local region. The replication to all other regions happens asynchronously.
When a client issues a read request, it can be directed to any one of the four replicas in the specified region. This is where the concept of eventual consistency really comes into play. The chosen replica may be in the process of updating and could return stale (old) data or, in some cases, no data at all.
While this may seem concerning, remember that eventual consistency aims to strike a balance between consistency, availability, and partition tolerance. It’s a compromise that offers benefits such as high availability and improved performance, especially in distributed scenarios where immediate consistency is not an absolute necessity.
Understanding the Trade-offs
Eventual consistency is ideal for scenarios where the system can tolerate some level of inconsistency. For instance, think of a social media platform displaying the number of likes for a post. If there is a slight lag showing the updated like count across various locations, it won’t significantly impact the user experience.
But, it’s important to understand that eventual consistency may not be suitable for applications that require strict consistency and immediate data reflection. For example, in a banking system, it’s critical that all nodes reflect the most recent transactions to avoid issues such as overdrafts.
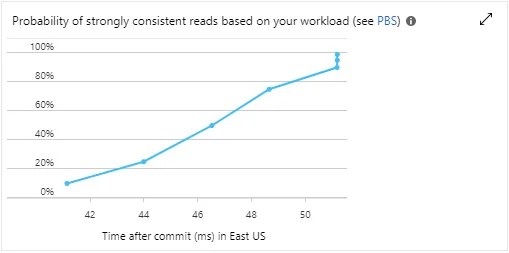
Understanding Probabilistically Bounded Staleness (PBS)
The Probabilistically Bounded Staleness (PBS) metric is a unique feature of Azure Cosmos DB that provides insights into the consistency behavior of your database. This metric effectively answers the question – How eventual is your eventual consistency?
PBS represents the probability, measured in milliseconds, of achieving consistent reads for a combination of write and read regions. It is exposed in the Azure portal and can be accessed to monitor the consistency behavior of your Cosmos DB account in real time.
The PBS metric can prove to be an invaluable tool when you need to balance between consistency requirements and performance. By monitoring the PBS metric, you can understand how often your database provides a stronger consistency than the level you’ve currently configured. For instance, if your Cosmos DB account is configured at the eventual consistency level, but the PBS metric shows a high probability of achieving session or consistent prefix consistency, you might choose to optimize your application for these higher consistency levels without incurring additional latency or throughput costs.
Use Cases for Each of the Consistency Levels Provided by CosmosDB
In this section we explore each of the consistency levels discussed earlier and the scenarios where they are most beneficial.
1. Strong Consistency
Use Case: Strong consistency is ideal for scenarios where data integrity and consistency are of utmost importance. Examples include financial applications like banking, where transactional integrity is crucial, and ensuring data consistency across all regions is more important than latency or availability.
2. Bounded Staleness Consistency
Use Case: Bounded staleness consistency is beneficial for applications that require near real-time consistency but can tolerate some delay. For instance, a news website could use this model to ensure articles are updated globally within a set time frame, maintaining a balance between consistency and performance.
3. Session Consistency
Use Case: Session consistency is widely used in scenarios where user-specific data is involved. Examples include e-commerce applications where a user’s shopping cart needs to be consistently updated within a session, or social media apps where a user’s actions (like posts or comments) must be immediately visible to them.
4. Consistent Prefix Consistency
Use Case: This consistency level is useful in scenarios where relative order of data is important, such as a messaging app where messages need to be displayed in the order they were sent and received.
5. Eventual Consistency
Use Case: Eventual consistency is perfect for scenarios where performance and availability are prioritized over immediate consistency. Examples include analytics platforms where data is collected from various sources, and slight staleness is acceptable, or social media apps where a slight delay in propagating likes or comments is tolerable.
Conclusion
In conclusion, the world of distributed databases is a complex one, with many factors to consider and trade-offs to make. However, with a solid understanding of consistency levels and the tools to manage them effectively, developers can harness the power of distributed databases to build robust, efficient, and user-friendly applications. The choice of the right consistency level is a critical step in this journey. Through this article, we hope to have given you a deeper understanding of this important topic and the confidence to make the right decisions for your distributed database applications.