In today’s fast-paced digital world, the ability to process and respond to data in real-time is a game-changer for businesses. Event-Driven Architecture (EDA) stands out as a powerful approach that enables systems to react instantly to events, enhancing responsiveness and scalability. At the heart of this architecture is Apache Kafka, a robust platform designed to manage high-throughput, real-time data streams with ease.
This post takes you on a deep dive into Event-Driven Architecture and the capabilities of Apache Kafka.

Part 1: Foundations of Event-Driven Architecture
Understanding EDA Principles
Event-Driven Architecture (EDA) is a design paradigm in which the flow of the program is determined by events such as user actions, sensor outputs, or messages from other programs. In EDA, the main components include:
- Events: Represent significant changes in state or conditions within the system. For example, a user clicking a button or a sensor detecting a temperature change.
- Producers: Components or services that generate and publish events. For example, a user interface that sends a click event.
- Consumers: Components or services that receive and process events. For example, a logging service that records click events.
- Event Sourcing: A practice where state changes are logged as a sequence of immutable events. This allows the state to be reconstructed by replaying the events.
The core benefits of EDA include:
- Improved Scalability: By decoupling components and relying on asynchronous communication, systems can scale more efficiently to handle varying loads.
- Loose Coupling: Components interact through events, reducing dependencies and making the system more modular and easier to maintain.
- Responsiveness: Systems can react to events in real-time, improving user experience and enabling timely data processing.
Benefits and Challenges of EDA
- Benefits:
- Increased Agility: EDA allows for rapid adaptation to changing requirements and environments due to its modular nature.
- Resilience: Independent components can fail without bringing down the entire system, enhancing overall system reliability.
- Improved Developer Experience: Developers can focus on individual components, making it easier to understand, test, and maintain the system.
- Challenges:
- Distributed System Complexity: Managing a system where components are distributed and communicate asynchronously can be complex.
- Debugging Difficulties: Tracking down issues can be more challenging in an asynchronous system where events propagate through multiple services.
- Consistency: Ensuring data consistency across different services can be challenging, particularly in event-sourced systems.
Comparison with Traditional Architectures
Traditional Request-Response Architecture
- Synchronous Communication: Components directly call each other and wait for responses.
- Tight Coupling: Direct dependencies between components make the system less flexible and harder to scale.
- Single Point of Failure: A failure in one component can affect others, reducing system resilience.
Event-Driven Architecture:
- Asynchronous Communication: Components communicate through events, allowing for non-blocking operations.
- Loose Coupling: Components are decoupled, making the system more flexible and easier to scale.
- Resilience and Scalability: Independent components can handle failures gracefully and scale according to demand.
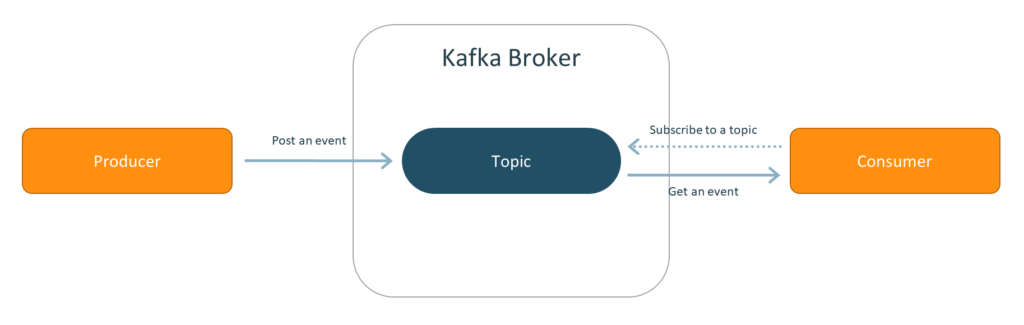
Part 2: Apache Kafka: The Powerhouse of Event Streaming
Introduction to Apache Kafka
Apache Kafka is a distributed streaming platform known for its ability to handle high-throughput, real-time data streams. At its core, Kafka is a publish-subscribe messaging system that allows applications to produce and consume streams of records efficiently.
- Publish-Subscribe Messaging System: Kafka enables multiple producers to send data to multiple consumers without the need for direct connections between them. This decoupling enhances system scalability and flexibility.
- High-Throughput Data Streams: Kafka is designed to handle vast amounts of data, making it ideal for applications that require real-time analytics, monitoring, and data integration.
Kafka Architecture Deep Dive
Understanding Kafka’s architecture is essential to leveraging its full potential. Kafka’s architecture comprises several key components:
- Topics: A topic is a logical channel to which producers send data and from which consumers read data. Each topic can be divided into multiple partitions to allow parallel processing.
- Partitions: Partitions are the fundamental units of parallelism in Kafka. Each partition is an ordered, immutable sequence of records, and new records are appended to the end.
- Replicas: Kafka maintains multiple copies of partitions (replicas) across different brokers to ensure data availability and fault tolerance.
- Producers: Producers publish data to Kafka topics. They can control which partition a record is sent to, allowing for key-based partitioning.
- Consumers: Consumers read data from Kafka topics. A consumer group is a group of consumers that work together to consume a topic’s partitions.
- Brokers: Brokers are Kafka servers that store data and serve client requests. A Kafka cluster is made up of multiple brokers, with one broker acting as the controller.
Setting Up and Running Kafka
Setting up Kafka involves several steps to ensure a functional and scalable cluster:
Installation:
- Download Kafka from the official Apache Kafka website.
- Extract the downloaded files to a directory of your choice.
Configuration:
- Zookeeper: Kafka relies on Zookeeper for cluster management. Configure Zookeeper by editing the `zookeeper.properties` file.
- Kafka Broker: Configure the Kafka broker by editing the `server.properties` file. Key settings include broker ID, log directory, and Zookeeper connection string.
Starting Kafka:
- Start Zookeeper: `bin/zookeeper-server-start.sh config/zookeeper.properties`
- Start Kafka Broker: `bin/kafka-server-start.sh config/server.properties`
Cluster Setup:
- To set up a multi-node cluster, replicate the configuration and startup process on additional servers, ensuring unique broker IDs and appropriate Zookeeper connection settings.
Hands-On Guide
Download Kafka:
wget https://downloads.apache.org/kafka/2.8.0/kafka_2.13-2.8.0.tgz
tar -xzf kafka_2.13-2.8.0.tgz
cd kafka_2.13-2.8.0
Start Zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.properties
Start Kafka Broker:
bin/kafka-server-start.sh config/server.properties
Create a Topic:
bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
Produce Messages:
bin/kafka-console-producer.sh --topic test --bootstrap-server localhost:9092
Consume Messages:
bin/kafka-console-consumer.sh --topic test --from-beginning --bootstrap-server localhost:9092
Part 3: Building Event-Driven Applications with Kafka
Producing and Consuming Events
To build event-driven applications with Kafka, you need to understand how to produce and consume events using Kafka APIs. Kafka clients are available for various programming languages, including Java and Python.
Producing Events (Java Example):
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<>("test", Integer.toString(i), "message-" + i));
}
producer.close();
}
}
Consuming Events (Java Example):
import org.apache.kafka.clients.consumer.*;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("test"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}
Building Microservices with Kafka
Kafka facilitates communication between microservices in an event-driven architecture by enabling asynchronous messaging. This decouples microservices, allowing them to operate independently and improving system resilience and scalability.
CQRS (Command Query Responsibility Segregation):
CQRS separates the read and write operations of a microservice into distinct models, optimizing each for performance and scalability.
Event Sourcing:
Event sourcing involves storing the state changes of an application as a sequence of events, providing a reliable audit log and enabling the reconstruction of past states.
Stream Processing with Kafka Streams
Kafka Streams is a powerful library for processing event streams in real-time. It allows you to filter, aggregate, and transform data streams using simple APIs.
Kafka Streams Example (Java):
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import java.util.Properties;
public class KafkaStreamsExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> stream = builder.stream("input-topic");
stream.filter((key, value) -> value.contains("important"))
.to("output-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}
Conclusion
Mastering Event-Driven Architecture (EDA) and Apache Kafka is a powerful combination that enables the design and implementation of robust, scalable, and real-time data processing systems. Through this comprehensive guide, we’ve explored the core principles and benefits of EDA, comparing it with traditional architectures to highlight its advantages in scalability, flexibility, and responsiveness.
We’ve delved into the fundamentals of Apache Kafka, understanding its architecture and key components like topics, partitions, producers, and consumers. This knowledge equips you to set up and run Kafka, providing a hands-on guide to creating and managing Kafka clusters. Moreover, we’ve covered the practical aspects of building event-driven applications, including producing and consuming events, developing microservices, and leveraging Kafka Streams for real-time data processing.
By integrating these concepts and tools, you can create efficient and resilient systems capable of handling high-throughput data streams, making real-time decisions, and scaling to meet growing demands. With the insights gained from this guide, you’re well-prepared to leverage Kafka’s full potential and design event-driven applications that are both innovative and impactful. Whether you’re building microservices, performing real-time analytics, or processing IoT data, Kafka and EDA provide the foundation for modern, dynamic, and high-performance systems.