Have you ever been captivated by a song playing in a cafe or at a friend’s place, but couldn’t identify it? Shazam (now Spotify) comes to the rescue! This ubiquitous app has revolutionized music discovery, instantly recognizing songs with just a few seconds of listening. But have you ever wondered how Shazam performs this seemingly magical feat?
This post delves into the fascinating world of Shazam’s music recognition technology. We’ll explore the powerful combination of databases Shazam utilizes to store a massive library of audio information and the clever algorithms that analyze your phone’s microphone input to match it with the perfect song. Get ready to discover the science behind the magic and unlock the secrets of Shazam’s music recognition prowess!
Shazam does not store the actual audio data of songs in its database. Instead, it uses an ingenious method known as audio fingerprinting to identify songs. Here’s how it works:
Audio fingerprinting is a technique that converts a song into a digital summary, or “fingerprint”, that can be easily compared with the fingerprints of other songs.

When a user submits an audio sample, Shazam’s algorithm generates a fingerprint for the submitted audio. This fingerprint is then matched against the stored song fingerprints in the database. The process involves:
- Audio Preprocessing: Noise reduction, volume normalization, and conversion to a digital format.
- Feature Extraction: Relevant acoustic features are extracted from the preprocessed audio, such as MFCCs, spectral features, and beat/t tempo detection.
- Fingerprint Generation: The extracted features are combined into a unique fingerprint representing the song’s sonic signature.
- Database Query: The generated fingerprint is used to query the database, searching for songs with similar acoustic features.
Let’s break down the process with a simple example:
Audio Fingerprinting: Imagine you have a song, and you want to add it to the Shazam database.
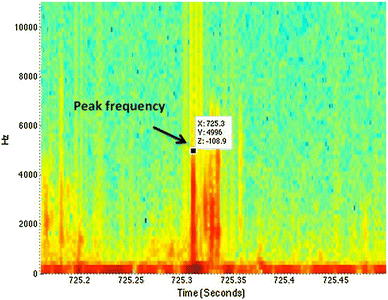
The first step is to convert the song into a spectrogram. This is a visual representation of the song where the x-axis represents time, the y-axis represents frequency, and the intensity of each point represents the amplitude of a particular frequency at a given time.
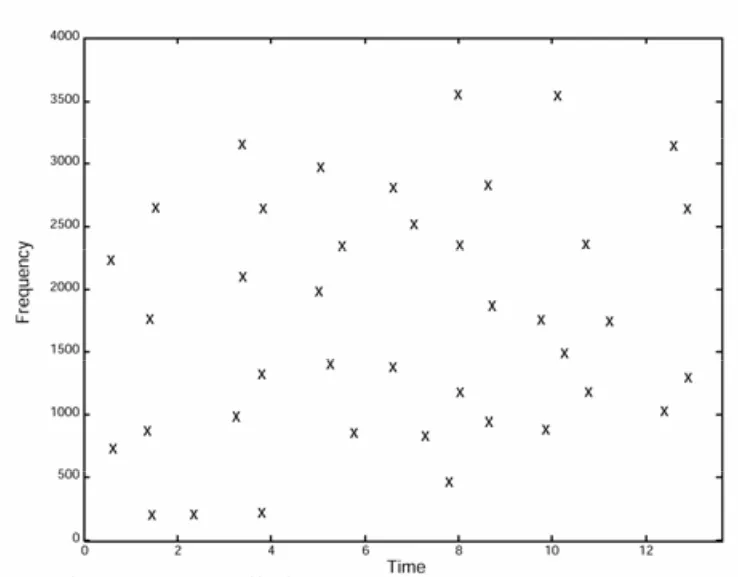
Creating the Fingerprint: The next step is to identify the peaks on the spectrogram, which correspond to the most intense or distinct parts of the song. Let’s say that in our song, the most intense frequencies occur at 5 seconds (500 Hz), 10 seconds (1000 Hz), and 15 seconds (1500 Hz). These points are then hashed using a function that turns the time-frequency pair into a single number. For instance, the peak at 5 seconds (500 Hz) might be hashed into the number 550, the peak at 10 seconds (1000 Hz) into the number 1010, and so on.
Storing the Fingerprint: The resulting fingerprint of our song might then be [550, 1010, 1515]. Along with this fingerprint, Shazam also stores metadata about the song, such as the title, artist, and album.
When a song is added to Shazam’s database, it creates an ‘audio fingerprint’ and collects metadata for the song.
The metadata includes information like the song’s title, the artist who performed it, the album it’s from, and so on. This is structured data, meaning it’s organized in a way that makes it easily searchable. Shazam stores this structured data in a MySQL database.
For example, if we take the song “Bohemian Rhapsody” by Queen, the metadata stored in the MySQL database might look like this:
- Song Title: Bohemian Rhapsody
- Artist: Queen
- Album: A Night at the Opera
- Year: 1975
The ‘audio fingerprint’ of the song, generated from the spectrogram as detailed before, is unstructured data. This is stored in a NoSQL database like MongoDB. NoSQL databases are good for storing large amounts of unstructured data and are efficient in handling read/write operations and horizontal scaling.
In our example, the fingerprint for “Bohemian Rhapsody” might look something like this in the MongoDB database:
- Fingerprint: [550, 1010, 1515]
Searching for Songs: Now, let’s say a user wants to identify a song they just heard. They use the Shazam app to record a short sample of the song. The app then repeats the same process: it converts the sample into a spectrogram, identifies the peaks, and generates a fingerprint. It then searches the database for this fingerprint. If it finds a match, it retrieves the song metadata associated with the fingerprint and displays it to the user.
Searching Process
When Shazam receives an audio recording, it creates a spectrogram of the sample, identifies the peaks and generates a fingerprint. This fingerprint is then used to search the databases.
NoSQL Database (MongoDB): In the NoSQL database, the fingerprint is used as the partitionKey. Suppose the recorded audio sample generates a fingerprint [500, 1000, 1500]. Shazam would then execute a query like this:
“`javascript
db.fingerprints.find({ fingerprint: { $in: [500, 1000, 1500] } })
“`
This may return a document like:
{
id: “60d5ec9af682fbd12a892c99”,
fingerprint: [500, 1000, 1500],
songId: “b7c9e2d7-5bfa-4cba-9e60-b6e1a4166e71”
}
The `songId` is the unique identifier associated with the fingerprint.
MySQL Database: After finding a matching fingerprint, Shazam retrieves the song ID and uses it to query the MySQL database. The song ID serves as the primary key in the MySQL database. Shazam would then execute a query like this:
“`sql
SELECT * FROM Songs WHERE songId = ‘b7c9e2d7-5bfa-4cba-9e60-b6e1a4166e71’
“`
This may return a row like:
songId: ‘b7c9e2d7-5bfa-4cba-9e60-b6e1a4166e71’,
title: ‘Bohemian Rhapsody’,
artist: ‘Queen’,
album: ‘A Night at the Opera’,
year: 1975
Handling Variable Number of Fingerprints
The system is designed to identify songs based on a subset of fingerprints. Even if the number of fingerprints in the audio recording is less than the number of fingerprints for the complete song, the system can still make a match. Shazam uses a pattern-matching algorithm to compare the sequence of fingerprints from the audio sample to the complete song.
For example, if the audio sample generates a sequence of fingerprints [500, 1000, 1500], [505, 1005, 1505], [510, 1010, 1510], the system will look for this sequence in the database. If it finds the sequence, it considers it a match even if the complete song has many more fingerprints.
This approach allows Shazam to scale and efficiently perform searches even as the number of songs and fingerprints in the database grows. The use of NoSQL for unstructured data (fingerprints) and SQL for structured data (metadata) allows for efficient storage and retrieval of data.
Scaling Music Fingerprinting
To handle massive volumes of data and scale the music fingerprinting process, Shazam employs strategies such as:
- Parallel Processing: Distributed computing and parallel processing accelerate feature extraction and fingerprint
generation. - Caching: Cache mechanisms reduce the number of database queries and improve search speed.
- Database Partitioning: Database is split into smaller partitions for efficient querying and retrieval.
- Indexing: A robust indexing system quickly locates relevant fingerprints in the database.
Shazam is a powerful music recognition system that uses innovative algorithms and database architectures to identify songs based on their acoustic features. By understanding how Shazam works, we can appreciate the complexity and elegance of this remarkable technology.
Your blog is a true gem in the world of online content. I’m continually impressed by the depth of your research and the clarity of your writing. Thank you for sharing your wisdom with us.
Thank you!