Key Value Store or Key Value Database
Key values can be string, integer, list, objects, etc. Value is treated as an unknown object in key-value store. Some examples of Key-Value stores are Memcached, Redis, etc. Kay value databases are highly partitionable and can be scaled horizontally to large extent compared to other databases.
- put(key ,value) : Adding key with value to the key-value store
- get(key) : Get value associated with key
- High Scalability: It should be able to handle sudden increase in load without issues by increasing instances.
- Consistency: It should provide consistent and correct response always.
- Durability: Data loss should not be there in case of network issues/ partition failure.
- Availability: It should be highly available and as per CAP theorem it should be CP system i.e. Consistency should take precedence over availability.
CAP Theorem
The CAP theorem mentions that a distributed system can deliver only two of three desired characteristics: consistency, availability, and partition tolerance.
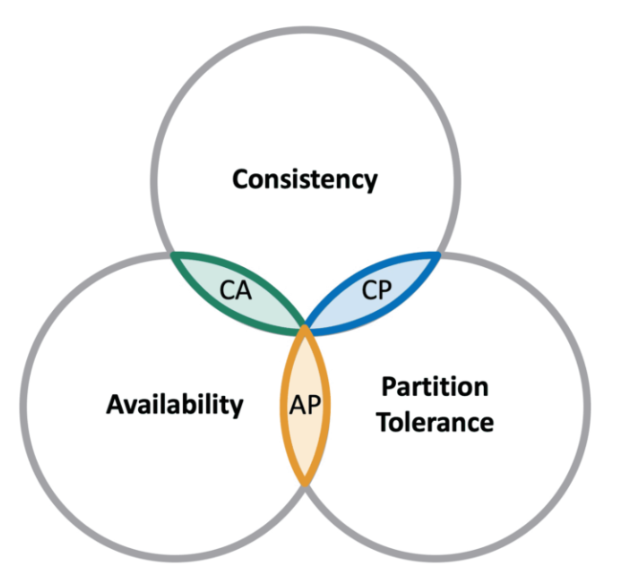
CP (Consistency and Partition Tolerance) systems: A CP system delivers consistency and partition tolerance at the expense of availability. When a partition occurs between any two nodes, the system has to shut down the non-consistent node (i.e., make it unavailable) until the partition is resolved.
AP (Availability and Partition Tolerance) systems: An AP system delivers availability and partition tolerance at the expense of consistency. When a partition occurs, all nodes remain available but those at the wrong end of a partition might return an older version of data than others. (When the partition is resolved, the AP systems typically resync the nodes to repair all inconsistencies in the system.)
CA (Consistency and Availability) systems: A CA system delivers consistency and availability across all nodes. It can’t do this if there is a partition between any two nodes in the system, however, and therefore can’t deliver fault tolerance. Since network failure is unavoidable a distributed system must tolerate network partition. CA system can not exist in ideal real-world distributed applications.
Which one to choose now CP or AP?
If consistency over availability is chosen then system must block all the write operations active nodes incase of anyone node going down to avoid data inconsistency. Thus system will be unavailable till the impacted node is up and running. For example : In case of banking applications high consistency is one of the major requirements so account information is provided accurately.
If availability over consistency is chosen then system will keep accepting reads even if it returns stale data. System will keep accepting writes at working nodes and data will be synced to node that is down once network partition is resolved.
Single Server Simple key-value store system
Creating key-value store for a single server is easy to understand as you will store the key-value pairs inside hash tables with everything stored will be in memory. Even if accessing data from memory is fast but saving everything in memory will be impossible due to space limitations. Still, for a single server there can be few optimizations done in order to fit more data such as: Instead of storing everything only store frequently used data in memory and rest everything in the disk, you can also compress your data before saving it in memory to save some space. Due to space constraint single server can’t be used for highly scalable distributed systems.
Distributed key-value store system
Distributed key-value store/ distributed hash table distributes key-value pairs across many servers.
Various components to build a key-value store:
- Data Replication
- Data Partition
- Consistency
- Failure Handling
Data Replication
Data Partitions
In large scale applications data can not fit inside single server and usually data is split into multiple partitions served across multiple partitions. We need to solve these challenges associated with data partitioning: Minimizing data movement when the number of nodes change and Distributing data evenly across multiple nodes. Good part is consistent hashing can be used to solve both these problems as it provides advantages such as: automatic scaling (Adding and removing servers based on load) and diversness (Number of virtual nodes to be allocated are proportional to the server capacity).
Consistency
As data is present across multiple servers/nodes thus synchronizing data between all the replicas is important. For example we have A2 replica for A1 machine now how can we be certain that both machines contain same data always? When adding a new data inside we must update both the machines but what if one of the fail write operation? As a result data will not be consistent in both the machines. Consistency can be achieved using some techniques such as:
Keeping a local copy at coordinator (proxy between client and nodes) incase update operation fail it can retry it.
Maintaining commit log such as in git, each node machine will record a commit log for each transaction. So before updating entry in machine A, we have to go through commit log first. A separate software will process all the commit logs and recover if an operations fails since we can look at the commit log.
Failure Handling
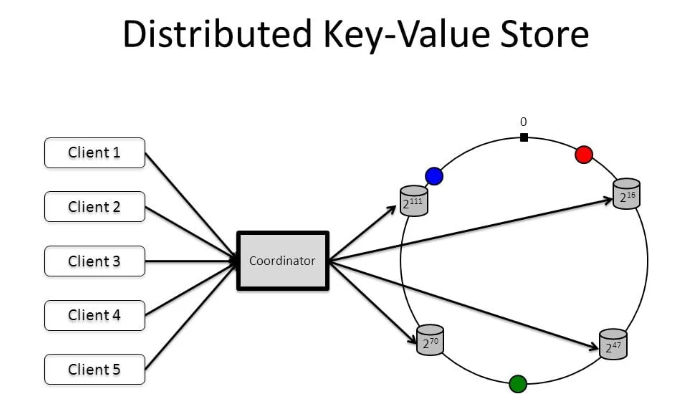
Client communicates with key-value store API endpoints : get(key) and put(key,value). Coordinator node acts as a proxy between client and the key value store. Nodes are distributed in a ring using consistent hashing. Data is replicated at multiple nodes. There will not be any single point of failute as every node has same responsibilities. Tasks performed by each node include: Failure detection, conflict resolution, replication, detection and resolution, etc.
Write and Read Paths
If data is not present in memory, it will be retrieved from the disk. Bloom filter is used to fetch data from SS Tables efficiently.