Music recognition system design sits at a nice intersection of signal processing and large-scale data systems. Apps like Shazam feel magical when they identify a song from a noisy five-second clip, but underneath is a tight pipeline: transform raw audio into a compact fingerprint, search that fingerprint efficiently, and map it back to human-friendly metadata.
From raw audio to fingerprints
Shazam does not store raw audio for every track. That would be expensive and slow to search. Instead it uses audio fingerprinting to convert each song into a compact digital summary that is fast to compare.
High-level pipeline
- Take a raw audio file.
- Clean it and convert it into a consistent digital format.
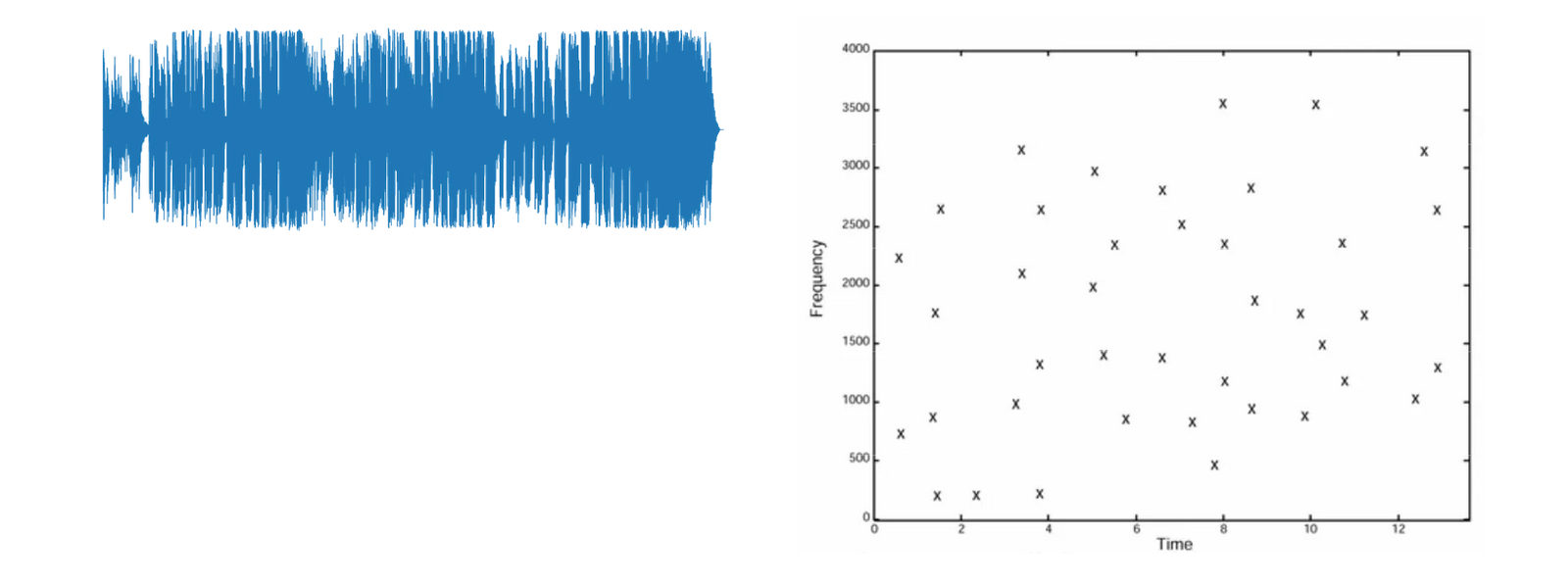
- Turn it into a spectrogram (time on x-axis, frequency on y-axis, intensity as amplitude).
- Detect distinctive peaks in that spectrogram.
- Hash those peaks into integers and store them as the song’s fingerprint.
- Keep human-readable metadata alongside the fingerprint.
sequenceDiagram
participant User
participant App as Shazam App
participant FP as Fingerprinting Service
participant NSQL as NoSQL Fingerprint DB
participant SQL as SQL Metadata DB
User->>App: Record short audio sample
App->>FP: Send audio data
FP->>FP: Preprocess audio (noise, normalize)
FP->>FP: Spectrogram + peak detection
FP->>FP: Generate fingerprint array
FP->>NSQL: Query by fingerprint
NSQL-->>FP: Matching fingerprint + songId
FP->>SQL: Query metadata by songId
SQL-->>FP: Title, artist, album, year
FP-->>App: Match result
App-->>User: Display identified song
This separation (fingerprint vs metadata) is key: the heavy signal processing happens once per track; most requests are just matching and lookup.
Audio preprocessing and feature extraction
Audio preprocessing
Before you can fingerprint, you need consistent input:
- Noise reduction: suppress background sounds from cafes, cars, or chatter.
- Volume normalization: quiet and loud recordings treated consistently.
- Format conversion: standard digital format and sample rate.
The goal is to make different recordings of the same song look similar enough in the next steps.
Spectrogram and peak detection
Shazam computes a spectrogram:
| Axis / property | Meaning |
|---|---|
| x-axis | Time |
| y-axis | Frequency |
| intensity | How strong a frequency is at a specific time slice |
From that spectrogram it picks peaks: time–frequency pairs where the energy is strong and distinctive. Example:
(t = 5s, f = 500 Hz)
(t = 10s, f = 1000 Hz)
(t = 15s, f = 1500 Hz)Those peaks are passed into a hash function that combines time and frequency into a single integer:
(5s, 500 Hz) → 550
(10s, 1000 Hz) → 1010
(15s, 1500 Hz) → 1515The fingerprint becomes a short array, e.g.:
[550, 1010, 1515]This representation is small, robust to noise, and easy to index.
Data model: NoSQL for fingerprints, SQL for metadata
Shazam splits storage into two different systems, each optimized for its job.
NoSQL for unstructured fingerprints
Fingerprints are unstructured numeric arrays. They live in a NoSQL database such as MongoDB. The fingerprint field acts as a partition key or query key. Example document:
{
"id": "60d5ec9af682fbd12a892c99",
"fingerprint": [500, 1000, 1500],
"songId": "b7c9e2d7-5bfa-4cba-9e60-b6e1a4166e71"
}The store is tuned for high write throughput and fast read queries on these fingerprints.
SQL for structured metadata
Song metadata is structured and fits well in a relational model. It lives in a SQL database such as MySQL. songId is the primary key. Example row from a Songs table:
| Column | Value |
|---|---|
songId | b7c9e2d7-5bfa-4cba-9e60-b6e1a4166e71 |
title | Bohemian Rhapsody |
artist | Queen |
album | A Night at the Opera |
year | 1975 |
Joins are simple: one table for songs, others for albums, artists, or licensing. This split lets each database do what it is good at: NoSQL for messy, scalable fingerprint search; SQL for clean relational metadata.
Query path when you tap the Shazam button
When a user wants to identify a track, the flow mirrors the ingest pipeline.
Step 1: Capture and fingerprint
- The app records a short audio clip.
- The backend runs: preprocessing → spectrogram generation → peak detection → fingerprint generation.
Example: the new sample yields a sequence of fingerprint arrays:
[500, 1000, 1500]
[505, 1005, 1505]
[510, 1010, 1510]Step 2: Fingerprint lookup
The service queries the NoSQL database with the sample’s fingerprint values:
db.fingerprints.find({
fingerprint: { $in: [500, 1000, 1500] }
})That returns one or more candidate documents:
{
"id": "60d5ec9af682fbd12a892c99",
"fingerprint": [500, 1000, 1500],
"songId": "b7c9e2d7-5bfa-4cba-9e60-b6e1a4166e71"
}The important field is songId.
Step 3: Metadata lookup
Using that songId, the service queries the SQL database:
SELECT *
FROM Songs
WHERE songId = 'b7c9e2d7-5bfa-4cba-9e60-b6e1a4166e71';That returns the human-friendly metadata, which is sent back to the app and shown to the user.
Matching with partial fingerprints
Real users often record only a few seconds, and the environment is noisy. Shazam’s design accepts that:
- It does pattern matching on sequences of fingerprints.
- Even if a sample contains fewer fingerprints than the full track, the system can match based on overlapping subsequences.
- A sequence like the three arrays above can still be matched inside a much longer fingerprint sequence for the full song.
This tolerance is what makes the system robust when only a short, imperfect clip is available.
Scaling music fingerprinting
At scale, Shazam has to handle millions of tracks and continuous user queries. Strategies:
Parallel processing
- Feature extraction and fingerprint generation are embarrassingly parallel.
- Distributed workers can process different songs or segments at the same time.
- This accelerates ingest when the catalog grows or when re-fingerprinting is needed.
Caching
- Caches reduce repeated database hits for hot songs.
- Frequently requested
songId→ metadata lookups can be served from in-memory caches like Redis.
Partitioning and indexing
- Partitioning splits fingerprint data across shards so queries can fan out and run in parallel.
- Indexes on fingerprint values and sequences make lookups fast even with large catalogs.
Together these patterns let music recognition stay fast as the catalog and user base expand.
Concept map of the architecture
graph TD
A[Audio file] --> B[Preprocess audio]
B --> C[Generate spectrogram]
C --> D[Detect peaks]
D --> E[Generate fingerprint array]
E --> F[Store in NoSQL fingerprints DB]
E --> G[Map to songId]
G --> H[Store metadata in SQL Songs table]
One pipeline builds the fingerprints and metadata. At query time, the same steps up to E run on the user sample, then the system walks F and H in reverse to get back to a song.
Key takeaways
- Audio fingerprinting converts songs into compact, peak-based fingerprints that are robust to noise and short samples.
- Spectrograms and peak hashing turn time and frequency information into integers that are easy to store and index.
- NoSQL is used for fingerprints because it handles large, unstructured arrays and high-throughput queries well.
- SQL is used for metadata since song data is structured and benefits from relational modeling and primary keys.
- Partial sequence matching lets the system identify songs from only a few seconds of audio.
- Scaling comes from parallel processing, caching, partitioning, and indexing, which together keep lookup times low as the catalog grows.
// SPONSORSHIP
If this research saved you time or improved your architecture, consider sponsoring my work on GitHub. All sponsorships go directly toward infrastructure and further technical research.
[ Become a Sponsor ]