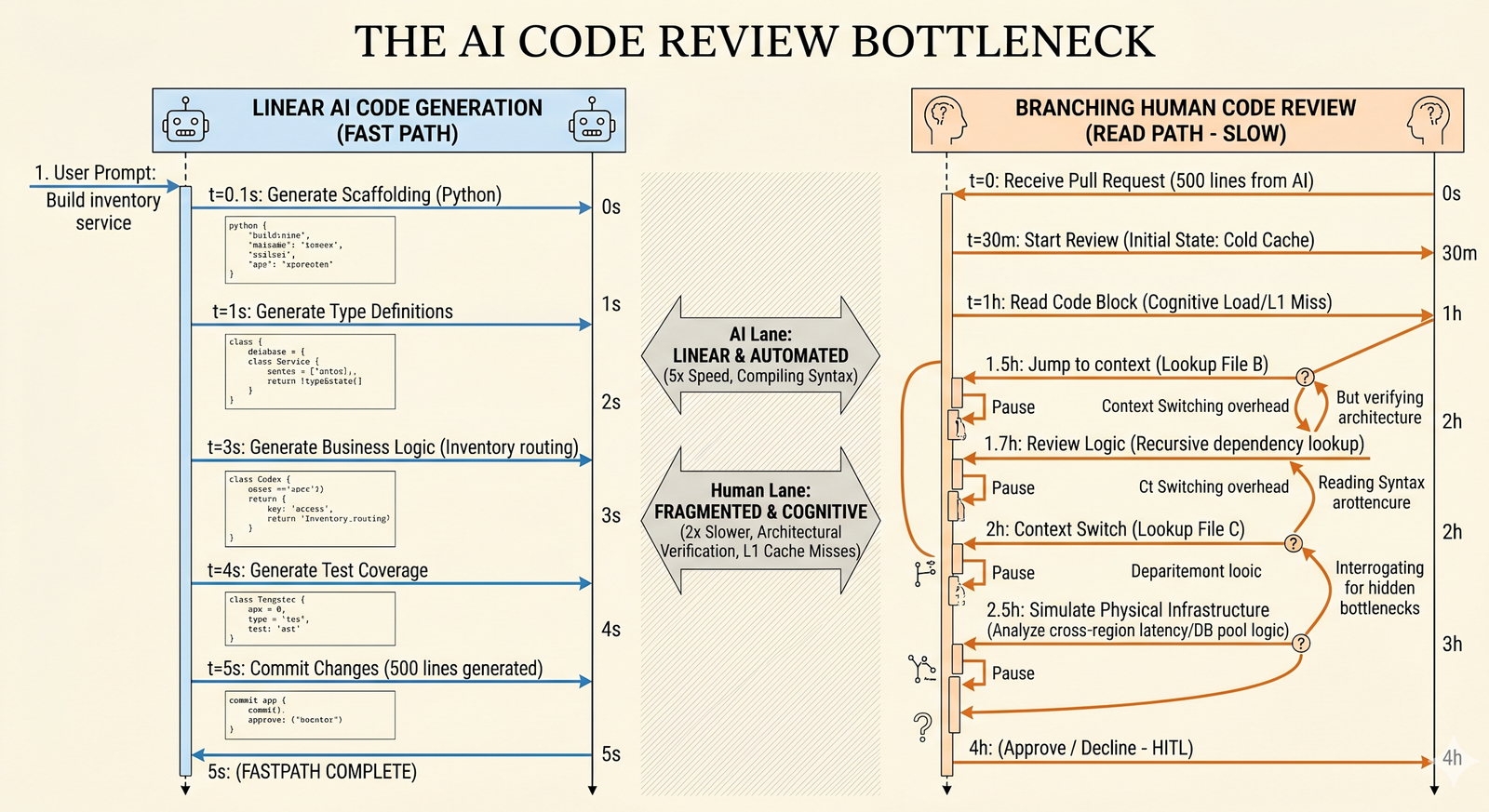
The Mismatch Between Write and Review Velocity
I keep coming back to the same problem: the write path is now a race, but the review path is still a crawl.
AI tools let me generate a new feature branch in minutes. The machine handles boilerplate, test scaffolding, and even the edge cases.
But when I hand that work to a reviewer, the real cost shows up.
A 400-line PR can take an engineer twice as long to review as it took to write. That is not because the code is bad. It is because the reviewer is playing catch up with context, architecture, and real world cost.
Why Review Feels Like an I/O Bound Operation
Writing code is a local operation. I have the problem statement in my head, I know the data model, and I am operating in a narrow part of the stack.
Reviewing code is not like writing it. The reviewer starts cold. They need to load the proposed behavior into their working memory. They jump between files, parse data flow, and mentally simulate the hardware and network.
The Hardware and Network Cost of Modern Review
When the code touches network boundaries, the review cost spikes.
An AI assistant can stitch together a service call to a legacy system, some retry logic, and a fan out to a remote region. The code can compile cleanly.
A reviewer has to do the hard work.
They must estimate the latency of each hop. They must judge whether the connection pool will collapse under sustained traffic. They must think about TCP queue behavior, thread hold time, and whether a cloud provider will charge for cross region traffic.
This is not a software problem alone. It is hardware and architecture.
The Real Cost of One Bad Review
If a reviewer misses a hidden network hop, the first failure mode is slow.
The second is failure.
A function call across regions adds raw latency. That latency keeps worker threads occupied longer. The database connection pool fills. The system stops accepting new requests.
The cost of a missed architectural assumption is not a code smell. It is a saturated queue, a degraded cluster, and a production incident.
sequenceDiagram participant Dev as Developer participant AI as AI assistant participant PR as Pull request participant Rev as Reviewer Dev->>AI: generate feature branch AI-->>PR: push large diff Rev->>PR: fetch diff Rev->>Rev: reconstruct architecture Rev->>PR: identify network boundaries Rev-->>PR: request clarifications
How to Make Review Match the Speed of Writing
The work should not be about complaining that review is slow. It should be about changing the flow.
- Keep PRs small. If AI wrote it, the change should not exceed 100 lines.
- Put the cost in the description. State the endpoint count, external hops, and expected latency.
- Show the network boundary up front. A tiny diagram in the PR description is worth ten comments.
- Prefer synchronous review for architecture changes. If the reviewer has to rebuild the whole mental model, talk it through.
Why This Matters
AI can be a force multiplier. It is also a traffic generator.
The write path has improved. The review path has not.
If we want delivery velocity that holds in production, we have to treat review as a hardware problem too.
We need better PR hygiene, better cost signals, and a review process that honors the actual systems we build.
// SPONSORSHIP
If this research saved you time or improved your architecture, consider sponsoring my work on GitHub. All sponsorships go directly toward infrastructure and further technical research.
[ Become a Sponsor ]